
Data groeit bij vrijwel elk bedrijf in hoog tempo. De vraag is allang niet meer óf je data opslaat, maar hóe je dat slim doet: efficiënt, veilig en zonder onnodige kosten. Gegevensopslag optimaliseren draait om het verlagen van de totale kosten van je opslaginfrastructuur — inclusief alles eromheen — terwijl prestaties, beveiliging en compliance op peil blijven, en bij voorkeur verbeteren. Een centraal onderdeel van zo’n aanpak is slimme tiering: data staat niet allemaal op hetzelfde type opslag, maar wordt verdeeld over meerdere opslaglagen. Veelgebruikte data staat op snelle opslag; data die je zelden opent, staat op goedkope opslag. Zo bespaar je aanzienlijk, terwijl je IT-omgeving goed blijft functioneren.

Het gaat dus niet alleen om “minder uitgeven”, maar om weloverwogen keuzes die op lange termijn waarde opleveren. De balans vinden tussen lage kosten, voldoende capaciteit, goede prestaties, groei en het voldoen aan beveiligings- en compliance-eisen is de kern. Cloudprijzen en cloudgebruik fluctueren voortdurend, waardoor kostenbeheer een doorlopend proces is dat vraagt om meetgegevens, analyses en automatisering. Uiteraard moet data te allen tijde veilig zijn, ongeacht waar die zich bevindt. Voor organisaties die extra sterke bescherming in de cloud willen integreren in een bredere datastrategie, is het de moeite waard om te kijken naar veiligste cloud opslag.
Wat betekent gegevensopslag optimaliseren en waarom is het belangrijk?
Gegevensopslag optimaliseren is geen losstaande IT-truc, maar een praktische noodzaak. Het is een combinatie van technieken en tools om data zo efficiënt mogelijk op te slaan en beschikbaar te houden: de juiste opslagplek kiezen die past bij het gebruik, zonder concessies te doen aan snelheid of beveiliging. Het is ook geen eenmalige actie, want datavolumes, gebruikspatronen en organisatiebehoeften blijven veranderen. Het doel is helder: de totale eigendomskosten (Total Cost of Ownership, TCO) van je data-infrastructuur verlagen en tegelijkertijd meer waarde uit je data halen.
Waarom dit zo urgent is, blijkt uit de cijfers. Uit een Flexera-enquête (2023) blijkt dat organisaties gemiddeld 28% van hun public cloud-uitgaven verspillen, vaak aan resources die nauwelijks of niet worden benut. Optimalisatie helpt dus om geld te besparen, resources beter in te zetten, prestaties te verbeteren en ruimte vrij te maken voor innovatie. Zonder een doordacht plan kunnen opslag- en beheerkosten snel oplopen en de concurrentiekracht van een bedrijf ondermijnen. Gegevensopslag optimaliseren is daarmee een fundament voor een gezonde IT-omgeving en een wendbare organisatie.
Belangrijkste uitdagingen bij groeiende datavolumes
Meer data biedt kansen, maar legt ook druk op IT-teams. Een groot knelpunt is de moeilijk te voorspellen aard van cloudkosten. In plaats van vaste kosten betaal je op basis van gebruik, en dat kan per maand sterk variëren. Die flexibiliteit is handig om snel op te schalen, maar maakt budgettering en kostensturing ingewikkelder. Veel organisaties stapten naar de cloud in de verwachting dat het direct goedkoper zou worden, maar kregen al snel te maken met wisselende rekeningen en inefficiënt gebruik. Cloud draait immers niet alleen om kostenbesparing, maar bovenal om flexibiliteit en schaalbaarheid.
Een tweede probleem is wat we ‘dataophoping’ kunnen noemen. Veel organisaties geven aan dat tot 60% van hun opgeslagen data nooit wordt gebruikt, maar opruimen staat zelden hoog op de agenda. Dat komt door de hoeveelheid werk die ermee gemoeid is, het risico iets weg te gooien dat later toch nodig blijkt, en de moeite om intern goedkeuring te krijgen. Daarbij ontbreekt het vaak aan inzicht in wat cloudgebruik werkelijk kost. Veel monitoringtools tonen prestaties, maar niet altijd de financiële impact. Het gevolg: te veel resources, meer verspilling, hogere kosten én extra druk op duurzaamheidsdoelstellingen.
Infrastructuurkosten: waar ontstaan ze?
IT-infrastructuurkosten komen uit meerdere bronnen. Er zijn directe kosten voor hardware en software — servers, storage, netwerken en licenties. In de cloud worden dat abonnementen en verbruikskosten voor rekenkracht (compute), opslag en netwerk. Cloudproviders rekenen doorgaans per actieve server, opgeslagen data, dataverkeer, databases en aanvullende diensten zoals analytics of beveiliging. Door complexe prijsmodellen betalen organisaties vaak te veel, bijvoorbeeld wanneer beheerders een zwaardere — en duurdere — compute-instantie kiezen dan nodig is.
Dataverkeerkosten zijn een veelgehoorde verrassing. Cloudproviders rekenen regelmatig voor het verplaatsen van data tussen regio’s, beschikbaarheidszones of zelfs tussen diensten binnen hetzelfde platform. Wie data vaak kopieert of verplaatst, ziet die kosten snel oplopen. Inefficiënte processen voor data-ophalen, overbodige overdrachten en onvoldoende toepassing van deduplicatie of compressie verergeren dit. Vergeten resources, ongebruikte softwareabonnementen en betaalde maar onbenutte capaciteit zorgen er verder voor dat de totale kosten onnodig hoog blijven. Net zoals bij spouwmuurisolatie geldt ook hier: wie vooraf goed checkt wat er werkelijk nodig is, voorkomt onnodige uitgaven achteraf.
Welke opslaglagen zijn er en wat zijn hun kosten en prestaties?
Wie opslag wil optimaliseren, moet begrijpen welke opslaglagen er bestaan en wat de verschillen zijn in prijs en snelheid. Opslag wordt ingedeeld in lagen die aansluiten bij hoe snel je data nodig hebt, hoe lang je het bewaart en wat het budget toelaat. Dit principe noemen we tiering. De redenering is eenvoudig: dure, snelle opslag is niet nodig voor data die je zelden raadpleegt. Hoe vaker en hoe sneller je data nodig hebt, hoe duurder de bijbehorende opslaglaag.
Doorgaans onderscheiden we drie categorieën: ‘heet’, ‘warm’ en ‘koud’. Elke laag past bij een ander type data. Wie data in de verkeerde laag plaatst, betaalt te veel (koude data op dure opslag) of krijgt trage systemen (actieve data op archiefopslag). De juiste verdeling is dus de sleutel tot lagere kosten én goede prestaties.
Verschil tussen snelle, middensegment en archiefopslag
De drie hoofdlagen, met hun doel en typisch gebruik:
De hete laag (hot storage) is de snelste opslag, doorgaans gebaseerd op SSD of NVMe. Deze laag is bestemd voor data die frequent wordt opgevraagd en waarbij lage latency cruciaal is, zoals productiedatabases, transactiesystemen en real-time analytics. Snelheid staat voorop — en dat vertaalt zich in een hogere prijs.
De warme laag (warm storage) zit daar tussenin. De kosten liggen lager dan bij hot storage, met nog steeds acceptabele snelheid. Deze laag is geschikt voor data die periodiek wordt gebruikt: kwartaalrapporten, recente back-ups, logbestanden voor kortetermijnanalyses of projectbestanden die nog actief zijn. Vaak gaat het om snelle HDD-opslag of minder snelle SSD-opslag.
De koude laag (cold storage), ook wel archiefopslag, is de goedkoopste optie. Bedoeld voor data die zelden of nooit wordt geraadpleegd, maar die langdurig bewaard moet blijven — denk aan wettelijke bewaarplichten, oude bestanden, langetermijnback-ups of historische data voor incidentele analyse. Het ophalen duurt langer (soms minuten tot uren), maar de prijs per GB is laag. Denk aan object storage met lage toegangsfrequentie, tape of zeer dichte HDD-opslag.
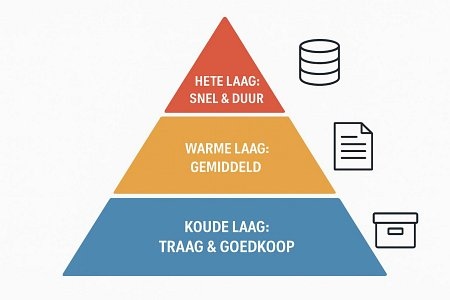
Kostenstructuur voor verschillende opslagtypen
De prijs hangt nauw samen met snelheid en toegankelijkheid:
- Hete laag: het duurst, door snelle hardware en hogere operationele kosten (stroom en koeling). In de cloud betaal je vaak ook meer voor I/O-bewerkingen en soms voor dataverkeer.
- Warme laag: een evenwichtiger model. De prijs per GB ligt lager dan bij hot storage; I/O-kosten zijn beperkt of minder frequent van toepassing.
- Koude laag: de laagste prijs per GB. Let op de kosten voor data-ophalen (retrieval fees) en de langere wachttijd. Hierdoor ongeschikt voor data die snel beschikbaar moet zijn, maar ideaal voor archivering en compliance. Met slimme tiering kun je opslagkosten afstemmen op werkelijk gebruik en zo tot wel 30% besparen.
Prestatieverschillen en geschikte toepassingen per opslaglaag
De lagen verschillen voornamelijk in latency en IOPS:
Opslaglaag
Prestaties
Typische data
Voorbeeldtoepassingen
Heet
Hoogste IOPS, laagste latency
Actief en bedrijfskritisch
Databases, virtualisatie, real-time systemen, HPC
Warm
Middel
Regelmatig gebruikt
Documentbeheer, rapportage, dev/test, datawarehouse voor periodieke analyses
Koud
Laag, hoge latency
Zelden gebruikt, lange bewaartermijn
Archief, compliance, langetermijnback-ups, historische analyse
De juiste laag kiezen per dataset verlaagt kosten én borgt de juiste prestaties per workload.
Wat is slimme tiering en hoe werkt het bij gegevensopslag?
Slimme tiering — ook wel automatische datatiering — is een beheeraanpak waarbij data automatisch wordt verplaatst tussen hot, warm en cold storage op basis van beleidsregels en feitelijk gebruik. In plaats van handmatig te bepalen waar alles thuishoort, gebruikt het systeem automatisering: veelgebruikte data gaat naar snelle opslag, nauwelijks gebruikte data naar goedkope opslag.
Dit werkt uitstekend voor kostenbeheer: je hoeft niet alles op dure storage te bewaren. Je behoudt goede prestaties voor cruciale workloads en verlaagt de kosten voor inactieve of archiefdata. Veel oplossingen analyseren toegangspatronen en maken soms gebruik van machine learning om zich aan te passen aan veranderingen in gebruik.
Definitie van slimme tiering
Slimme tiering is een geautomatiseerd proces dat data gedurende de gehele levenscyclus beheert door het te verplaatsen tussen opslaglagen. Die keuze is gebaseerd op factoren zoals gebruiksfrequentie, leeftijd van de data, bedrijfsbelang en geldende compliance-eisen. Het doel is een optimale balans tussen kosten, snelheid en beschikbaarheid — en dat evenwicht wordt continu bijgesteld, in plaats van eenmalig vastgelegd.
Het “slimme” aspect zit in algoritmes die toegangspatronen analyseren en inschatten welke data binnenkort nodig is. Op basis daarvan — en van de beleidsregels die je instelt — kiest het systeem de meest geschikte opslaglaag. Dat vermindert handmatig beheer en maakt storagegebruik structureel efficiënter.
Hoe gegevens automatisch worden geclassificeerd en geplaatst
Een slim tieringsysteem werkt doorgaans op basis van beleidsregels die IT-beheerders vastleggen. Veelgebruikte criteria zijn:
- Toegangsfrequentie: hoe vaak wordt data gelezen of aangepast?
- Leeftijd van de data: nieuwe data start vaak ‘heet’ en schuift naarmate de tijd verstrijkt door naar koudere lagen.
- Datatype en bedrijfsbelang: kerngegevens voor applicaties blijven langer in hot storage.
- Compliance: bepaalde data moet op een voorgeschreven manier of voor een vaste periode worden bewaard.
Na het instellen van de regels monitort het systeem continu de activiteit. Het analyseert metadata en gebruik — bijvoorbeeld hoe lang een bestand niet is geopend — en deelt data in als actief, inactief of archief. Vervolgens verplaatst het de data automatisch naar de juiste laag. Een bestand dat zes maanden niet is geopend, kan zo automatisch van SSD naar goedkope object storage worden verplaatst. Voor gebruikers blijft data bereikbaar, al kan het bij koude opslag iets langer duren voordat een bestand beschikbaar is.

Voorbeelden van tieringoplossingen in de praktijk
Slimme tiering wordt breed ingezet, zowel in de cloud als on-premises:
- In de cloud: AWS (S3 Intelligent-Tiering, Glacier), Azure (Blob Storage-lagen) en Google Cloud (Storage-klassen) bieden opslagklassen waarbij data automatisch doorschuift op basis van gebruik. Bij S3 Intelligent-Tiering kan een object bijvoorbeeld automatisch verplaatsen tussen frequent, infrequent en archief — zonder handmatige tussenkomst.
- On-premises: SAN/NAS-oplossingen met software-defined storage kunnen SSD’s en verschillende typen HDD’s combineren en data dynamisch verdelen. Leveranciers als NetApp, Dell EMC en HPE bieden dergelijke systemen.
- Hybride aanpak: actieve, gevoelige data blijft lokaal op snelle opslag, terwijl minder gevoelige of oudere data naar goedkope cloudopslag gaat. Deze mix is een effectieve tieringvorm om kosten te beheersen en prestaties te borgen waar dat nodig is.
Voordelen van slimme tiering voor langdurige infrastructuurkosten
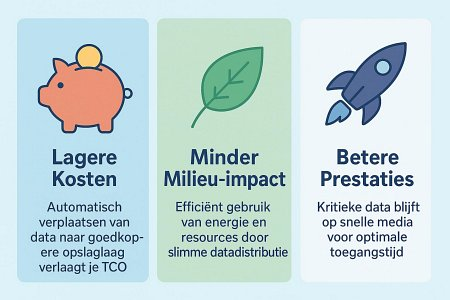
Slimme tiering levert niet alleen directe besparingen op storage op. Het beïnvloedt ook de efficiëntie van je gehele IT-omgeving en de schaalbaarheid op lange termijn. Door storage beter te benutten, verklein je verspilling en krijg je meer grip op kosten — zichtbaar in een lagere TCO, maar ook in betere prestaties voor bedrijfskritische systemen.
Nu data blijft groeien en budgetten onder druk staan, biedt slimme tiering een praktische manier om opslagkosten beheersbaar te houden. Opslag is dan geen vaste kostenpost meer, maar iets dat je actief stuurt op basis van werkelijk gebruik.
Kostenbesparingen door geoptimaliseerd gebruik van opslaglagen
Het meest tastbare voordeel is dat je minder dure storage nodig hebt. Data die zelden wordt gebruikt, verhuist automatisch naar goedkopere archiefopslag. Daardoor hoef je niet alles op de snelste — en duurste — schijven te bewaren.
Besparingen kunnen oplopen tot circa 30% op opslagkosten. Het prijsverschil per GB tussen SSD en koude object storage is aanzienlijk. Wie veel data naar een goedkopere laag kan verplaatsen, ziet dat snel terugkomen op de factuur. Bovendien verklein je het risico op over-provisioning: capaciteit aanschaffen “voor de zekerheid” die vervolgens onbenut blijft. Tiering helpt uitgaven beter af te stemmen op werkelijke behoefte, zodat budget vrijkomt voor andere initiatieven. Meer inzicht in wat de cloud werkelijk kost helpt om die afweging goed te maken.
Vermindering van overbodige data en energieverbruik
Slimme tiering kan ook bijdragen aan het verminderen van overbodige data — en daarmee aan een lager energieverbruik. Met levenscyclusregels leg je vast wanneer data wordt verplaatst, gecomprimeerd of verwijderd. Dat pakt het eerdergenoemde probleem aan dat tot 60% van de opgeslagen data ongebruikt blijft. Minder dataophoping betekent een kleinere opslagvoetafdruk.
Een kleinere voetafdruk betekent minder actieve hardware, minder koeling en daarmee lagere operationele kosten. Dit ondersteunt bovendien duurzaamheidsdoelstellingen. Door resources slimmer toe te wijzen, daalt het energieverbruik en verkleint de milieu-impact van je datainfrastructuur.
Verbeterde prestaties en schaalbaarheid
Tiering gaat niet uitsluitend over kosten. Het kan prestaties juist verbeteren doordat veelgebruikte data op de snelste laag blijft. Dat levert lagere latency op voor kritische applicaties, snellere verwerking en een betere gebruikerservaring.
Ook opschalen wordt eenvoudiger. Je kunt capaciteit uitbreiden met goedkopere lagen zonder dat het budget direct explodeert. Het systeem past zich aan groei aan door data automatisch te verdelen, waardoor kostbare upgrades van de volledige storageomgeving minder vaak nodig zijn. In de cloud is opschalen al laagdrempelig; tiering zorgt ervoor dat je dat op een kostenefficiënte manier doet, met een betere verdeling van resources en meer stabiliteit voor de organisatie.
Slimme tiering implementeren: waar moet je rekening mee houden?
Slimme tiering invoeren gaat niet vanzelf. Het vraagt om planning, heldere keuzes en zorgvuldige uitvoering — en niet alleen op technisch vlak. Ook governance, duidelijke afspraken en samenwerking tussen teams zijn onmisbaar. Je moet de volledige levenscyclus van data in kaart brengen en nadenken over de impact op verschillende afdelingen.
Opslagoptimalisatie in de cloud — en tiering als onderdeel daarvan — vraagt ook een andere werkwijze. IT, finance en business moeten samen sturen op gebruik en kosten. Zonder die afstemming haal je minder uit de beschikbare tools, hoe goed die ook zijn.
Automatisering en monitoring van datastromen
Slimme tiering staat of valt bij automatisering en continue monitoring. Handmatig beheer is onhoudbaar bij grote datavolumes en vergroot de kans op fouten. Je hebt tools nodig die data kunnen classificeren, beleidsregels kunnen uitvoeren en verplaatsingen tussen lagen kunnen afhandelen. Cloudproviders bieden daarvoor vaak automatische schaalopties en Infrastructure as Code (IaC) om resources automatisch te provisioneren en aan te passen aan de vraag.
Monitoring is minstens zo belangrijk. Observability-tools geven inzicht in resourcegebruik, toegangspatronen en kosten, waarmee je verspilling opspoort, onverwachte kosten signaleert en uitgaven bewaakt in omgevingen met meerdere clouds. Heatmaps tonen wanneer de vraag hoog of laag is, zodat je diensten tijdelijk kunt afschalen. Stel ook waarschuwingen in op kosten- of gebruiksdrempels. Zonder dit soort monitoring merk je problemen pas wanneer de factuur binnenkomt.
Datagovernance, beveiliging en compliance-eisen
Datagovernance, beveiliging en compliance horen standaard in elk implementatieplan. Ze bepalen hoe data door de organisatie beweegt en hoe lang je het bewaart. Je moet weten welke data gevoelig is, welke bewaarplichten gelden (zoals de AVG of HIPAA) en welke beveiligingsmaatregelen per laag vereist zijn.
Beveiliging hoort in elke opslaglaag te zijn ingebouwd: encryptie van data in rust en in transit, role-based access control (RBAC) en auditlogs om acties te registreren. Cloudfuncties kunnen helpen dit goed in te richten zonder de kosten te laten ontsporen. Controleer regelmatig of je provider voldoet aan de geldende eisen en loop zaken als encryptie, toegangsbeheer, patchbeleid en privacymaatregelen periodiek door. Goed lifecycle-beheer — waar tiering een onderdeel van is — kan zowel kosten verlagen als de beveiliging versterken.
Integratie met hybride en multi-cloudomgevingen
Veel organisaties werken met een combinatie van eigen datacenters en meerdere cloudproviders. Tiering moet naadloos op deze omgevingen aansluiten. Dat vraagt om bewuste keuzes: welke data blijft on-premises (bijvoorbeeld vanwege legacy-systemen of hoge gevoeligheid), wat gaat naar de cloud, en hoe verplaats je data tussen die omgevingen?
Netwerkoptimalisatie is belangrijk om dataverkeerkosten te beperken en latency laag te houden. Edge computing kan helpen door bepaalde workloads dichter bij gebruikers te draaien, waardoor minder bandbreedte nodig is. Beheerplatforms die een integraal kostenoverzicht bieden voor hybride omgevingen zijn waardevol om uitschieters te identificeren. Ook de keuze voor de juiste provider speelt een rol: je wilt schaalbare infrastructuur, transparante prijzen en flexibele opties die kosten, prestaties en groei in evenwicht houden.
Best practices en valkuilen bij slimme tiering voor kostenoptimalisatie
Slimme tiering kan veel opleveren, maar alleen als je het goed aanpakt. Er zijn werkwijzen die het succes vergroten en valkuilen die zorgen voor gemiste besparingen of prestatieproblemen. Een tool aanzetten is niet genoeg; je hebt een aanpak nodig die continu wordt bijgesteld, met aandacht voor processen, mensen en governance.
Wie het meeste uit tiering wil halen, kijkt verder dan de techniek, leert van veelgemaakte fouten en onderneemt vooraf stappen om die te vermijden.
Veelvoorkomende fouten bij het toepassen van tiering
Een veelgemaakte fout is onvoldoende inzicht in werkelijk datagebruik. Zonder goede monitoring kun je geen doeltreffende beleidsregels opstellen. Wie tiering inricht zonder te weten welke data echt ‘heet’ of ‘koud’ is, laat data te lang op dure opslag staan of plaatst kritische data per ongeluk op trage archiefopslag — met performanceproblemen als gevolg.
Een tweede valkuil is het laten staan van inactieve of te ruim gedimensioneerde resources. Tiering lost niet alle verspilling op. Ongebruikte virtuele machines, vergeten opslagvolumes en overgedimensioneerde databases blijven kosten genereren. Regelmatige opschoning blijft noodzakelijk. Ook het ontbreken van een duidelijk FinOps-model (Financial Operations) is een probleem: wanneer IT, finance en business niet gezamenlijk sturen, worden tieringbeslissingen gefragmenteerd en minder effectief. Cloudkostenbeheer is een doorlopend proces, geen eenmalige controle.
Tot slot vormt onvoldoende kennis bij teams een risico. Als medewerkers niet begrijpen hoe tiering werkt en wat de gevolgen zijn voor toegangstijden en kosten, wordt het systeem suboptimaal benut en blijft het resultaat achter bij de verwachting.

Praktische aanbevelingen voor effectieve gegevensopslag optimalisatie
De volgende aanbevelingen helpen om tiering structureel goed te laten werken:
- Werk met FinOps: stel een multidisciplinair FinOps-team samen met IT, finance en business. Dit team maakt afspraken over kostenbeheer, tieringregels, budgetten en monitoring.
- Gebruik observability en AI-tools: zet monitoring en analyse in om gebruik en kosten inzichtelijk te maken. AI kan helpen bij het voorspellen van patronen en het automatisch bijstellen van resources.
- Stel duidelijke levenscyclusregels op: leg vast wanneer data doorschuift naar een koudere laag, gecomprimeerd wordt of verwijderd kan worden. Houd daarbij rekening met gebruik, leeftijd, datatype en compliance-eisen.
- Voer audits en rightsizing uit: verwijder ongebruikte resources en stem diensten af op de werkelijke behoeften van elke workload. Autoscaling kan hierbij ondersteunen.
- Maak gebruik van kortingen en besparingsplannen: overweeg reserved instances voor stabiele workloads en spot instances voor taken die vertragingstolerant zijn. Kijk ook naar savings plans en volumekortingen.
- Beperk dataverkeerkosten: vermijd onnodige verplaatsingen van data tussen regio’s en diensten. Ontwerp de datastroom zo efficiënt mogelijk.
- Train teams: investeer in cloudkennis en maak kostenbewustzijn een vast onderdeel van de werkcultuur. Organiseer gerichte trainingen.
- Begin klein en schaal op: start met een pilot voor één workload of dataset, meet het effect en breid de aanpak vervolgens stap voor stap uit.
Met deze aanpak maak je tiering beheersbaar en haal je er langdurig voordeel uit.
Veelgestelde vragen over gegevensopslag optimaliseren met slimme tiering
Hieronder beantwoorden we vragen die regelmatig terugkomen bij organisaties die slimme tiering willen inzetten. Ze gaan over toepasbaarheid, het meten van resultaten en de bijdrage aan duurzaamheid.
Is slimme tiering geschikt voor elke organisatie?
Ja, in de basis wel. Vrijwel elke organisatie met groeiende datavolumes en de wens om opslagkosten te beheersen kan profiteren van slimme tiering. De manier waarop je het inzet verschilt per organisatiegrootte en omgeving, maar de basisprincipes blijven gelijk.
Voor het mkb zijn cloudgebaseerde tieringoplossingen laagdrempelig: beperkte opstartkosten en relatief eenvoudig te configureren. Voor grote organisaties met hybride of multi-cloudomgevingen is tiering vaak nog belangrijker, omdat de datavolumes groter zijn en de besparingen snel kunnen oplopen. De uitdaging ligt hier vooral in integratie en centraal beheer.
Het succes hangt in grote mate af van de gekozen tools, de kwaliteit van de processen en de mate waarin kostenbewust werken in de organisatie is verankerd. Organisaties met veel archiefdata of sterk wisselend gebruik zien doorgaans de grootste winst.
Hoe meet ik de kostenbesparingen van tiering?
Kostenbesparing meet je het best met een gestructureerde aanpak:
- Nulmeting: leg vast wat je nu betaalt voor opslag en beheer, en hoe data momenteel is verdeeld over de lagen.
- Kostenmonitoring: gebruik tools van je cloudprovider of externe platforms om uitgaven en trends op resourceniveau bij te houden.
- Taggen van resources: voorzie resources van tags per afdeling, project of applicatie, zodat je kosten correct kunt toewijzen en de ROI kunt aantonen.
- Kosten per GB vergelijken: analyseer hoeveel data naar goedkopere lagen is verplaatst en wat dat doet met de maandelijkse uitgaven.
- Indirecte besparingen meenemen: denk aan minder beheerwerk, minder prestatieproblemen en een lager energieverbruik.
- Betere budgetprognoses: gebruik de verzamelde data om toekomstige opslagbehoeften en kosten beter te plannen.
Volgens McKinsey Digital kunnen technologieleiders door gerichte optimalisatie vaak snel 15 tot 25% besparen op cloudprogrammakosten.
Kan slimme tiering bijdragen aan duurzaamheid?
Ja. Slimme tiering ondersteunt duurzaamheidsdoelstellingen op meerdere manieren:
- Lager energieverbruik: actieve, snelle opslag verbruikt meer stroom. Door oudere of weinig gebruikte data naar zuinigere archiefopslag te verplaatsen, dalen het totale stroom- en koelverbruik.
- Minder nieuwe hardware nodig: efficiënter storagegebruik stelt de aanschaf van nieuwe hardware uit. Dat scheelt in productie, transport en elektronisch afval.
- Minder dataophoping: lifecycle-beheer helpt de berg ongebruikte data te verkleinen. Minder overbodige data betekent minder opslag en verwerking.
- Beter resourcegebruik: door cloudresources optimaler toe te wijzen en onderbenutting te verminderen, daalt ook de ecologische voetafdruk.
Slimme tiering helpt dus niet alleen bij het beheersen van kosten, maar draagt ook concreet bij aan het verminderen van de milieu-impact van dataopslag.
Conclusie
Gegevensopslag optimaliseren met slimme tiering is bovenal een stap naar structureel slimmer werken. Het gaat niet om een grote eenmalige omschakeling, maar om een aanpak waarbij je stap voor stap meer grip krijgt op kosten, prestaties en beheer. In plaats van cloud te beschouwen als “altijd goedkoper”, is het verstandiger te kijken hoe je met de cloud meer waarde levert: door betere keuzes, sterkere beveiliging en ruimte voor groei. FinOps speelt daarin een centrale rol, doordat kostenbeheer niet langer los staat van IT en business, maar er volledig mee verweven is.
Cloudkostenbeheer ontwikkelt zich steeds verder in de richting van “meer doen met minder”, waarbij automatisering en AI helpen bij het voorspellen van gebruik, het verdelen van resources en het reduceren van verspilling. Duurzaamheid krijgt daarin een vaste en groeiende rol. Organisaties die dit serieus oppakken, verwerven meer controle, kunnen sneller innoveren en staan sterker tegenover de concurrentie. Slimme tiering is een onmisbaar onderdeel van die ontwikkeling: het maakt opslag slanker, kosten beter voorspelbaar en IT-operations beheersbaar op schaal.
Comments are closed.